Python Libraries for DevOps
Day 15 of 90daysofdevops

I have been working as a Performance Engineer as well as Dynatrace Developer in TCS for 1 Year. I had interest in APM Tools, LoadRunner, AWS, Docker, Java, Python.
Libraries of Python used in DevOps
Python is a popular programming language used in DevOps for its simplicity and flexibility. There are several Python libraries commonly used in DevOps to automate tasks, manage infrastructure, and streamline the software development process. Here are some commonly used Python libraries in DevOps:
Ansible: Ansible is an open-source automation tool that allows you to manage and configure systems, deploy applications, and orchestrate tasks. It provides a simple and powerful way to automate infrastructure and application deployments.
Docker SDK for Python: Docker SDK for Python provides a Python API for interacting with Docker containers and Docker Swarm. It allows you to create, manage, and control Docker containers and services programmatically.
Kubernetes Python Client: Kubernetes Python Client is a Python library for interacting with Kubernetes clusters. It provides a Python API for managing Kubernetes resources, such as pods, services, deployments, and more.
Boto3: Boto3 is the Amazon Web Services (AWS) SDK for Python. It provides a Python API for interacting with various AWS services, such as EC2, S3, RDS, Lambda, and more. Boto3 is commonly used in DevOps for automating AWS infrastructure management and deployment.
PyTest: PyTest is a testing framework for Python. It allows you to write and run tests efficiently and supports features like test discovery, fixtures, assertions, and test parallelization. PyTest is often used in DevOps for automating testing processes.
JenkinsAPI: JenkinsAPI is a Python library that provides a programmatic interface to interact with the Jenkins Continuous Integration (CI) server. It allows you to manage jobs, trigger builds, retrieve build results, and perform other Jenkins-related tasks.
JSON in Python
JSON (JavaScript Object Notation) refers to a lightweight data interchange format that is commonly used for transmitting data between a server and a web application or between different parts of a software system. JSON is easy for humans to read and write and is also easy for machines to parse and generate.
In Python, the built-in JSON module provides functions for working with JSON data. This module allows you to encode (serialize) Python objects into JSON strings and decode (deserialize) JSON strings into Python objects.
the json.dumps() function is used to encode the Python object into a JSON string, and json.loads() is used to decode the JSON string into a Python object.
Here's a simple example that demonstrates encoding a Python object into a JSON string and decoding a JSON string into a Python object:
import json
# Encoding (Python object to JSON string)
data = {
"name": "Abhisek",
"age": 24,
"is_student": false,
"courses": ["Linux", "Git", "Python"]
}
json_str = json.dumps(data)
print(json_str) # Output: {"name": "Abhisek", "age": 24, "is_student": false, "courses": ["Linux", "Git", "Python"]}
# Decoding (JSON string to Python object)
json_data = '{"name": "Ashutosh", "age": 15, "is_student": true, "courses": ["Math", "Physics"]}'
python_obj = json.loads(json_data)
print(python_obj) # Output: {'name': 'Ashutosh', 'age': 15, 'is_student': true, 'courses': ['Math', 'Physics']}
YAML in Python
YAML (YAML Ain't Markup Language) refers to a popular data serialization format that is human-readable and commonly used for configuration files, data exchange, and storing structured data. It is designed to be easy for humans to read and write, while also being straightforward for machines to parse and generate.
The YAML format uses indentation and simple punctuation to represent data structures such as lists, dictionaries, and scalar values. It supports basic data types like strings, numbers, booleans, and null, as well as more complex structures.
# Example YAML document name: Abhisek age: 24 is_student: false interests: - reading - hiking address: street: 4th Cross, 12th Main city: Banglore country: IndiaIn Python, you can work with YAML files using the PyYAML library, which provides functions for reading and writing YAML data. You can install PyYAML using pip:
pip install pyyamlOnce installed, you can use PyYAML to load YAML data into Python objects and vice versa. Example:
import yaml # Load YAML data from a file with open('data.yaml') as file: data = yaml.safe_load(file) # Access data print(data['name']) # Abhisek print(data['age']) # 24 print(data['address']['city']) # Banglore # Modify data data['age'] = 25 data['interests'].append('cooking') # Save data to a YAML file with open('data_modified.yaml', 'w') as file: yaml.dump(data, file)
NOTE:
yaml.safe_load() is used to parse the YAML data from a file and create a corresponding Python object. The data can then be accessed and modified like any other Python object. Finally, yaml.dump() is used to write the modified data back into a YAML file.
Task
Create a Dictionary in Python and write it to a JSON File.
import json emp_details = { "Name":"Abhisek Moharana", "Age":24, "Branch":"Computer Science" } print(emp_details) with open("emp.json","w") as file: json.dump(emp_details,file)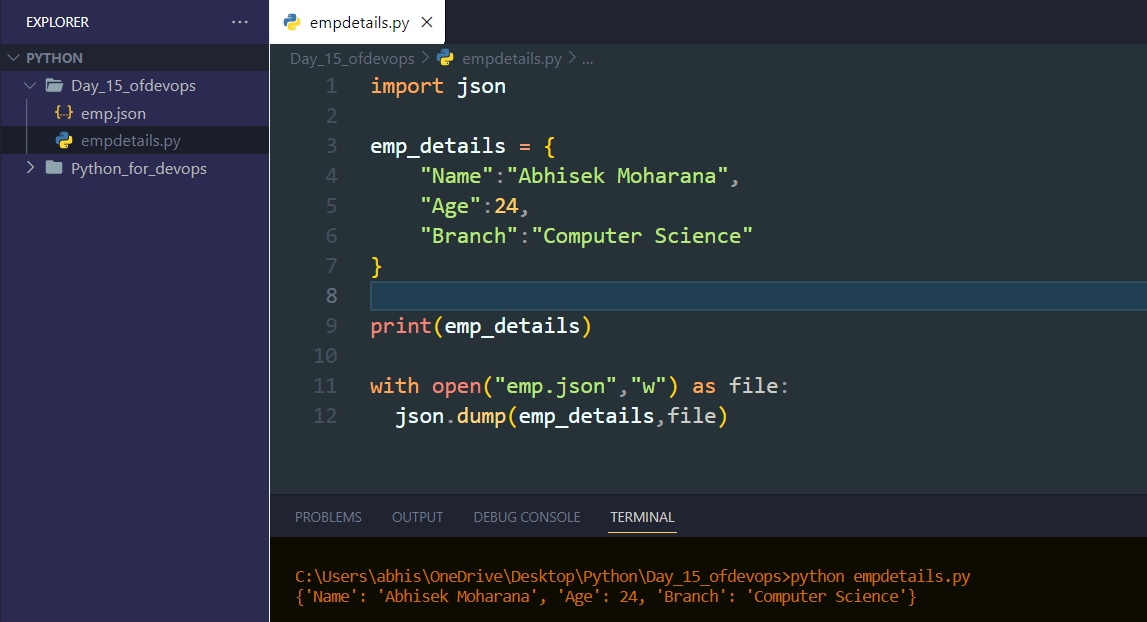
Read a JSON file services.json kept in this folder and print the service names of every cloud service provider.
// services.json { "services": { "debug": "on", "aws": { "name": "EC2", "type": "pay per hour", "instances": 500, "count": 500 }, "azure": { "name": "VM", "type": "pay per hour", "instances": 500, "count": 500 }, "gcp": { "name": "Compute Engine", "type": "pay per hour", "instances": 500, "count": 500 } } }import json with open("services.json") as s: data = json.load(s) print("aws: ", data['services']['aws']['name']) print("azure: ", data['services']['azure']['name']) print("gcp: ", data['services']['gcp']['name'])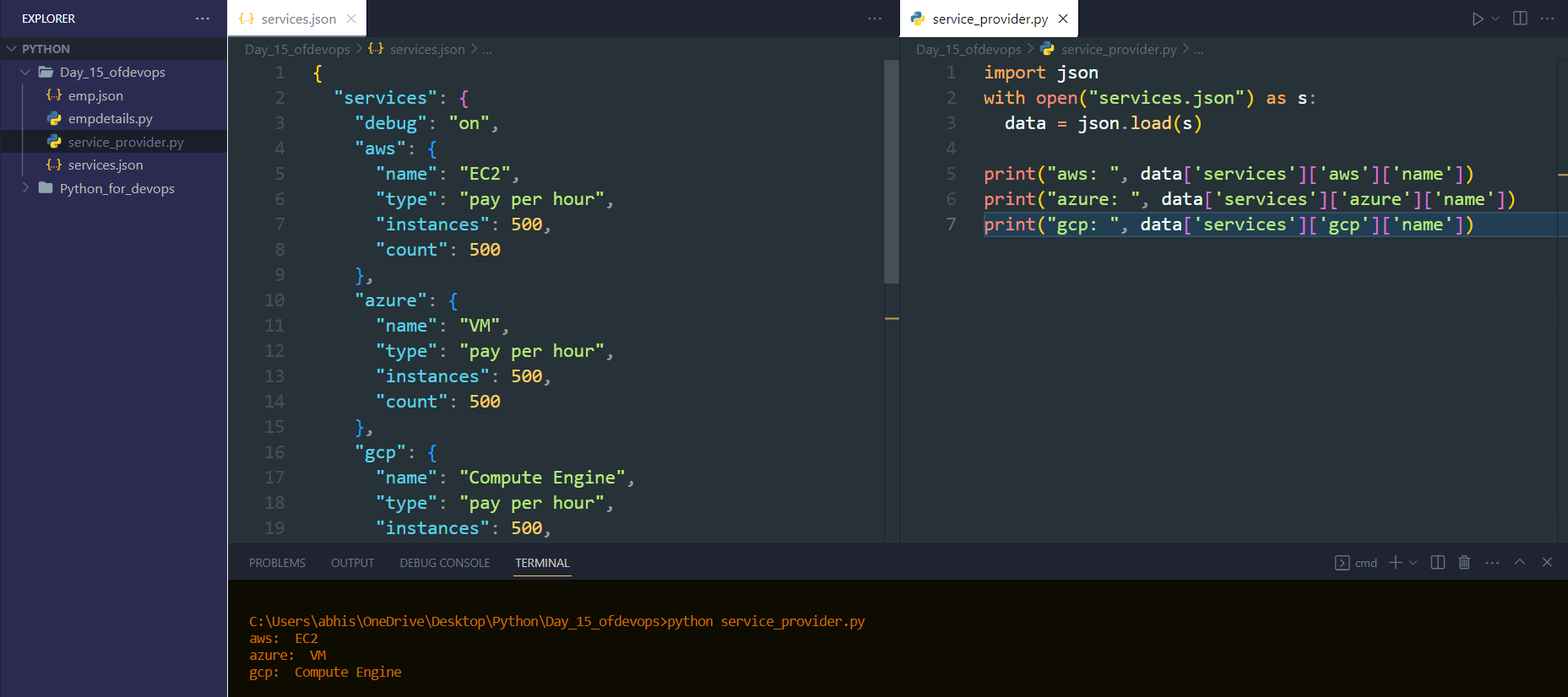
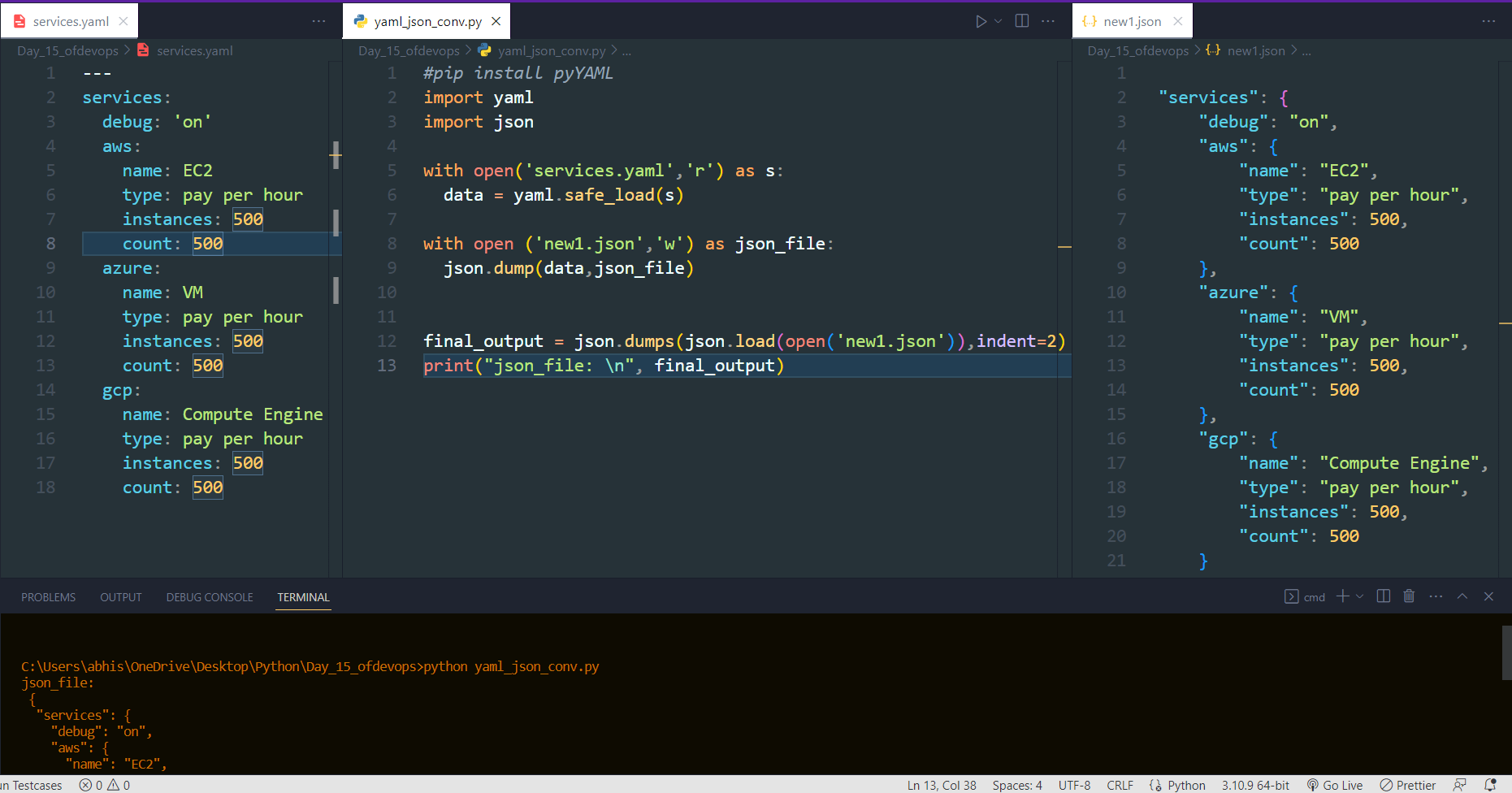
Read YAML file using python, file services.yaml and read the contents to convert YAML to JSON
#pip install pyYAML
import yaml
import json
with open('services.yaml','r') as s:
data = yaml.safe_load(s)
with open ('new1.json','w') as json_file:
json.dump(data,json_file)
final_output = json.dumps(json.load(open('new1.json')),indent=2)
print("json_file: \n", final_output)
services:
debug: 'on'
aws:
name: EC2
type: pay per hour
instances: 500
count: 500
azure:
name: VM
type: pay per hour
instances: 500
count: 500
gcp:
name: Compute Engine
type: pay per hour
instances: 500
count: 500
Thank You,
Abhisek Moharana




